

Automated Data Quality Management in Databricks
Overview
Databricks is a cloud-based data platform that integrates data engineering, machine learning, and analytics into a unified workspace. Built on Apache Spark, it enables organizations to efficiently process and analyze large datasets. The platform supports a variety of data formats and provides tools for real-time data processing, making it suitable for diverse applications, including data preparation and machine learning model development. Databricks’ architecture promotes collaboration among data scientists, engineers, and analysts, streamlining workflows and enhancing productivity. Its unique Lakehouse model combines the best features of data lakes and warehouses, addressing the complexities of modern data management.
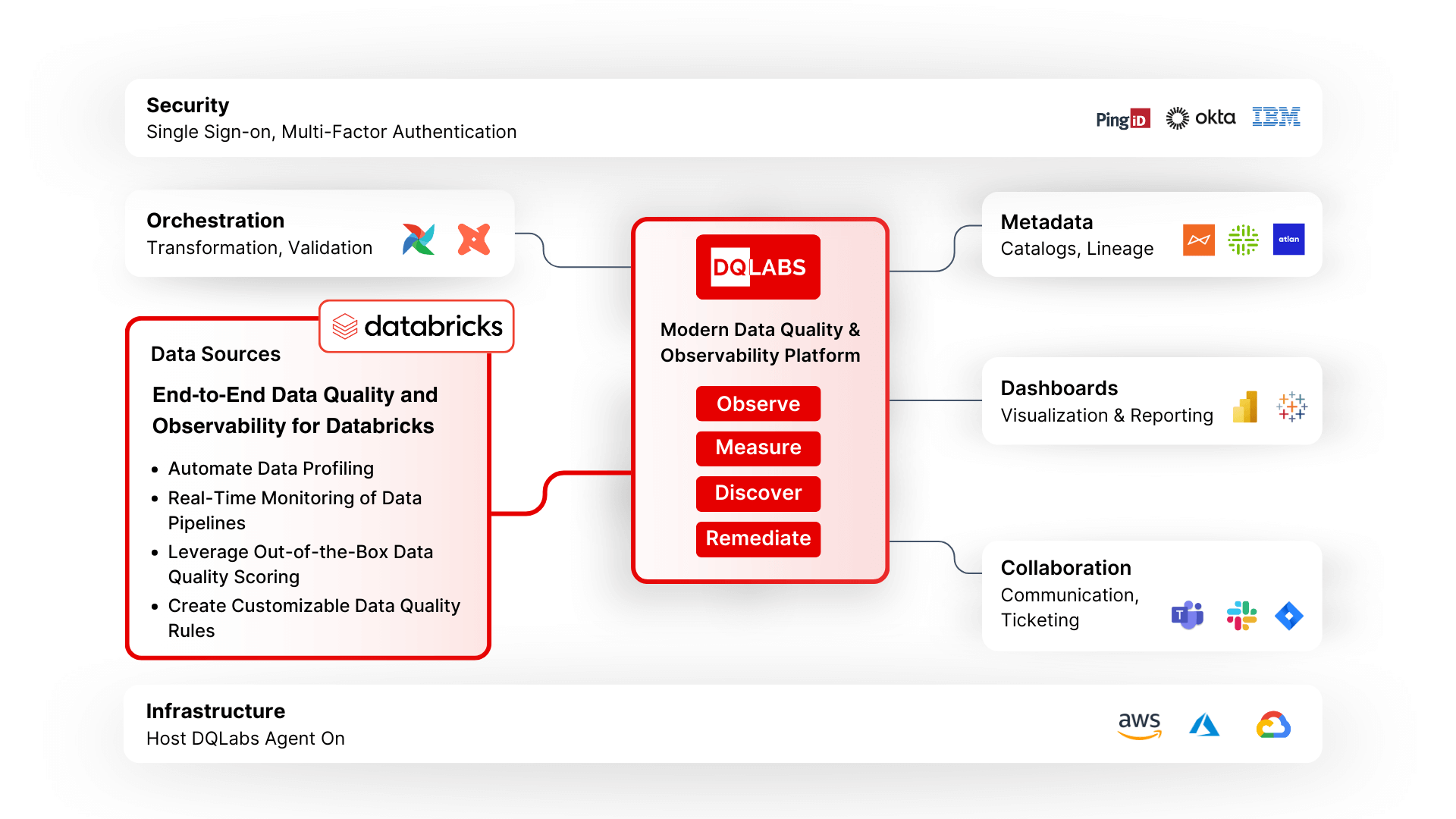
DQLabs allows organizations to easily discover and profile data assets within their Databricks environment. Users can search for specific data (e.g., email information) across all organizational assets, including those stored in S3 and managed through Glue Data Catalog or Tableau. The platform supports out-of-the-box capabilities for data profiling, enabling users to assess data quality across different stages of processing within Databricks, without extensive coding. DQLabs can utilize Databricks’ compute power by running Spark SQL queries or leveraging the existing Spark instance, allowing for processing without moving data out of Databricks. DQLabs allows users to select specific attributes of interest, focusing on business-critical data rather than analyzing the entire dataset. This targeted approach helps avoid overwhelming the system with unnecessary information. This integration also enables out-of-the-box data observability for Databricks to reduce data downtime. Just connect and monitor data across your modern data lakehouse for data quality issues and remediation in minutes.